よく分からなかったのでまとめ。言葉が違うことが原因の模様。
- 汎化誤差の期待値
- バイアス
- 学習アルゴリズムにおいて、誤差のうち、モデルの仮定の誤りに由来する分
- バイアスが大きすぎることは、入力と出力の関係を適切に捉えられていないことを意味し、過少適合
- こいつをRMSE的に捉えると理解できる
- データ同化では、エラーとバイアスを使い分けるので、混乱しやすい
- バリアンス
- 誤差のうち、訓練データの揺らぎから生じる分。
- バリアンスが大きすぎることは、本来の出力ではなく、訓練データのランダムなノイズを学習していることを意味し、過剰適合している。
- 高バリアンスは過学習だと思えば良い(overfitting)
- overfitting しているから、少し入力xが変わるだけで、f(x)が大きく変わる == 高バリアンス
- ノイズ
- 観測ノイズ。絶対になくならない
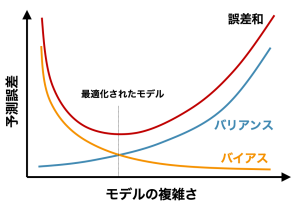
- トレードオフ
- バイアスとバリアンスはトレードオフ
- 高バイアス&低バリアンス
- 低バイアス&高バリアンス
- アンサンブル学習は、低バイアス&低バリアンスに持っていきたい
- スタッキング:学習器の出力を再び学習器にかける層をstackしていく
- バギング:単純な出力結果の重み付け平均 (e.g. Random Forest)
- ブースティング :弱学習器の出力を次の弱学習器にかける (e.g. Adaboost, Xgboost, lightgbm)
- バイアスとバリアンスはトレードオフ
- バイアス
- WIKIPEDIA 偏りと分散
- イメージ
- https://axa.biopapyrus.jp/machine-learning/model-evaluation/bias-variance-tradeoff.html